
이 글을 읽은 후에 아래 질문에 답할 수 있게 됩니다.
- 정규화가 무엇이고, 각 종류에 대해 설명해주세요.
- 왜 제2 정규형는 제1 정규형이 필수로 선행돼야 할까요?
- 왜 제3 정규형은 제2 정규형이 필수로 선행돼야 할까요?
- 실제로 제3 정규형의 조건인 '비주요 속성 -> 비주요 속성' 함수 종속성 해결은 제 2정규형 때 하는 '후보키 부분 집합(후보키 내 속성) -> 비주요 속성' 함수 종속성 해결과 위치를 바꿔도 무관합니다. '후보키 부분 집합(후보키 내 속성) -> 비주요 속성 -> 비주요 속성'의 함수 종속성이 있는 릴레이션을 생각해보죠! 앞을 먼저 끊든 뒤를 먼저 끊든 아무 문제가 없습니다. 근데 왜 우린 앞을 먼저 끊어야할까요?
- 제 1정규화를 하면 제2 혹은 3 정규화까지 만족시키는 경우도 있습니다. 왜그럴까요?
- 정규화 상태는 높을 수록 좋을까요?
- 역정규화란 무엇일까요? 이걸 왜할까요?
앞 이상현상이란? 함수 종속성이란? 정규화란? 꼬리 질문하며 살펴보자 글에서 이상현상과 함수 종속성이란 무엇인지 알아봤습니다. 이번 글에서는 정규화에 대해 알아보겠습니다. 이상현상과 함수 종속성을 잘 모르거나 애메하게 아시는 분들은 앞 글을 읽고 오시길 바랍니다. 자 그럼 정규화가 왜 필요하게 됐는지 알아보며 글을 시작하겠습니다.
글을 읽으시면서 핵심 부분(노란)과 꼬리질문(초록) 부분에 집중하며 읽어주세요! 개인적으로 키워드에서 꼬리질문을 하는게 개념을 깊이있게 이해하는 과정이라고 생각합니다:)
릴레이션을 잘못 설계하면, sql 문의 결과가 원하는 바와 다르게 나옵니다. 이를 이상현상이라고 합니다. 구체적으로 이상 현상은 후보키가 아니면서 결정자인 속성(비후보키 결정자 속성)이 있을 때 발생합니다. 이렇게 릴레이션 규칙이 제대로 지켜지지 않을 때 이를 바로잡아야 DB는 우리가 원하는 대로 작동할겁니다. 릴레이션 세계의 규율을 정상화라고 부를 수 있습니다. 한문으로 풀면 규율(법 규 規)을 정상(바를 정 正) 화(될 화 化)입니다. 이는 정규화(正規化)라고 하죠.
정규화에 대해 알아봅시다!
[단어]
주요 키(primary-key): a primary key is a specific choice of a minimal set of attributes (columns) that uniquely specify a tuple (row) in a relation (table). [7]
주요 속성(prime-attribute): The columns in a candidate key are called prime attributes [6]
후보 키(candidate key): A candidate key, or simply a key, of a relational database is a minimal superkey. [6]
비주요 속성(non-prime attribute): column that does not occur in any candidate key is called a non-prime attribute. [6]
*단어를 명확히 알고 넘어가시길 바랍니다! 책마다 다른 단어를 쓰기 때문에 영문으로 이해하는게 좋습니다.
목차
1. 정규화란?
2. 제1 정규화
3. 제2 정규화
4. 제3 정규화
5. BCNF 정규화
6. 프로젝트 적용
7. 마무리 질문
1. 정규화란?
정의: 데이터베이스 정규화는 데이터의 중복을 줄이고 데이터 무결성을 개선하기 위해 정규형으로 데이터베이스를 구조화 하는 과정이다.
정의에 따르면 정규화란 데이터베이스를 정규형으로 구조화 하는 과정이다! 그럼 정규형에는 어떤 것들이 있을까? 어떤 기준으로 정규형을 나눴을까? 간단하게 각 정규형의 정의를 훓어보고 정규화 & 정규형의 큰 그림을 살펴보자. 그 후 각각을 세세히 파헤쳐보자.
제1정규형: 어떠한 속성 도메인도 릴레이션을 요소로 가질 수 없다. (=릴레이션 속성은 단일 값이어야 한다)
제2정규형: 제1정규형이면서, 어떤 비주요 속성도 후보키의 부분 집합에 함수적으로 종속하지 않음.
제3정규형: 제2정규형이면서, 모든 비주요 속성이 후보키에만 종속하고 다른 키에 이행적으로 종속하지 않는 경우.
BCNF정규형: 제3정규형이면서, 모든 결정자가 후보키인 조건을 만족.
출처: DB normalization(wikipedia)에 따르면 관계형 데이터베이스는 3NF가 됐을 때 정규화됐다고 'often' 얘기합니다. '대부분'의 3NF는 삽입 이상, 삭제 이상, 수정 이상에 자유롭다고 합니다. 근데 왜 저는 BCNF 정규형까지 정리했을까요? 맞습니다. 'often'과 '대부분' 때문이죠. 실제로 출처: BCFN(wiki)에 의하면 관계형 스키마가 BCNF 정규형일 때, 함수 종속성에 의한 모든 중복은 없어진다고 합니다. 따라서 정규화는 BCNF까지 하는게 안전하겠죠!

정규형 하나 하나를 살펴보기 전에 정규형 간의 포함 관계를 짚고 가려 합니다. 위 정의에서 말했듯, 제N정규형은 제N-1정규형이 만족되어야 의미가 있습니다. 이는 정규형 간의 포함 관계가 존재하기 때문입니다. 그렇다면 왜 이런 관계가 형성됐는걸까요? 이럴땐 초기 목적을 다시 생각해보는게 도움이 됩니다.
우리는 이상현상을 제거하고 싶었습니다. 이상현상은 후보키가 아니면서 결정자인 속성(비후보키 결정자 속성)이 있을 때 발생했죠. 즉 이상현상은 모든 결정자인 속성이 후보키면 됩니다! 그렇죠. BCNF 정규형이 이에 해당합니다. 우리의 목표는 BCNF 정규형을 만드는겁니다! 포함관계가 왜 생겼을까?에 대한 의문만 가진채 계속 진행해보죠. 차차 풀릴겁니다.
BCFN 정규형을 만들어봅시다. 모든 결정자인 속성이 후보키려면 어떻게 할까요? 문제를 일으키는 원인을 살펴봅시다! 어떤 함수 종속성이 데이터 중복을 일으키고 데이터 무결성을 해칠까요? 앞으로 말하는 주요 속성은 주요 키가 아닌 주요 키 내 속성 하나 하나 혹은 부분 집합으로 생각하셔도 무방합니다.
- 후보키 부분 집합(후보키 내 속성) -> 비주요 속성
- 비 주요 속성이 후보키 부분 집합에 함수적으로 종속하는 경우
- 비주요 속성 -> 비주요 속성
- 비주요 속성이 비주요 속성에 함수적으로 종속하여 주요 키와 이행적 종속 관계일 경우.
- 비주요 속성 -> 후보키 내 속성
- 주요 속성이 비주요 속성에 함수적으로 종속하는 경우
- 후보키 내 속성 -> 후보키 내 속성
- 주요 속성이 주요 속성에 함수적으로 종속하는 경우
자 위 네개가 어떻게 4가지 정규형을 만드는 과정에 녹아있는지 살펴봅시다!
2. 제1정규형
정의: 어떠한 속성 도메인도 릴레이션을 요소로 가질 수 없다. (=릴레이션 속성은 단일 값이어야 한다)
제거 유형
- 릴레이션의 속성 값이 복수의 값을 가질 경우.
미제거 유형
- 비주요 속성이 후보키 부분집합에 종속하는 경우 제거됨.
- 비주요 속성이 다른 비주요 속성에 종속하는 경우
- 주요 속성이 비주요 속성에 종속하는 경우
- 주요 속성이 주요 속성에 종속하는 경우
Unnormalized form[1]은 정규화가 되지 않은 데이터입니다. ISBN#이 표의 키입니다. 자 이제 이를 정규화시켜보죠!

UNF(Unnormalized form)을 제1 정규형으로 바꾸면 아래와 같이 됩니다!

의문이들겁니다! 분명 우린 네가지의 종속성에 대해 얘기하고 있지 않았나? 맞습니다! 우린 관계형 데이터베이스 내 릴레이션이 가지는 네가지 함수 종속성 문제에 대해 살펴보고 있었죠. 근데 만약 릴레이션 내 데이터가 관계형 데이터베이스의 정의와 맞지 않으면 네가지 함수 종속성 문제를 해결하는게 의미가 있을까요? 우린 먼저 올바른 재료를 만들어야 합니다. 속성 도메인이 릴레이션을 요소로 가지는건 올바른 재료가 아닙니다. 이는 관계형 모델이 아닌 계층형 모델입니다. 관계형 모델은 데이터간의 관계를 자료간의 키(Key)에 의해 논리적 연결을 해야합니다. 이를 하기 위해선 속성 도메인이 단일 값을 가지는게 좋습니다. 이외에도 단일 값 특징은 단순한 자료 구조 구축, 관계대수 연산의 용이성의 장점을 가지고 있습니다.

The rationale for normalizing to 1NF [2]
- Allows presenting, storing and interchanging relational data in the form of regular two-dimensional arrays. Supporting nested relations would require more complex data structures.
- Simplifies the data language, since any data item can be identified just by relation name, attribute name and key. Supporting nested relations would require a more complex language with support for hierarchical data paths in order to address nested data items.
- Representing relationships using foreign keys is more flexible, where a hierarchical model only can represent one-to many relationships.
- Since locating data items is not directly coupled to the parent-child hierarchy, the database is more resilient to structural changes over time.
- Makes further normalization levels possible which eliminate data redundancy and anomalies.
3. 제2정규형
정의: 제1정규형이면서, 어떤 비주요 속성도 후보키의 부분 집합에 함수적으로 종속하지 않음.
제거 유형
- 비주요 속성이 후보키 부분집합에 종속하는 경우 제거됨.
미제거 유형
- 비주요 속성이 다른 비주요 속성에 종속하는 경우
- 주요 속성이 비주요 속성에 종속하는 경우
- 주요 속성이 주요 속성에 종속하는 경우
자 이제 제1 정규형 릴레이션을 제2 정규형으로 만들어봅시다! 제 2정규화에서 제거될 함수 종속 유형은 '비주요 속성이 후보키 부분집합에 종속하는 경우'입니다. 그치만 위 First Normal form에는 후보키가 ISBN# 하나군요. 따라서 표를 살짝 바꿔줍시다. 아래 표는 {Title, Format} 복합키가 주요키입니다. 주요키는 후보키에 속하기도 하니 우리가 필요한 재료가 전부 생겼군요 ㅎㅎ

제1 정규형을 제2 정규형으로 바꾸면 아래와 같이 됩니다! Format 즉 후보키 부분 집합이 비주요 속성을 결정하고 있군요. 릴레이션 내에 릴레이션이 있으므로 분해를 해줍시다!

4. 제3정규형
정의: 제2정규형이면서, 모든 비주요 속성이 후보키에만 종속하고 다른 키에 이행적으로 종속하지 않는 경우.
제거 유형
- 비주요 속성이 다른 비주요 속성에 종속하는 경우
미제거 유형
- 주요 속성이 비주요 속성에 종속하는 경우
- 주요 속성이 주요 속서엥 종속하는 경우
비주요 속성인 Author과 GenreID가 비주요 속성인 Author Nationality와 Genre Name을 결정합니다. 그러므로 각각을 떼어네서 다른 릴레이션으로 만듭시다!

5. BCNF정규형
정의: 제3정규형이면서, 모든 결정자가 후보키인 조건을 만족.
제거 유형
- 주요 속성이 비주요 속성에 종속하는 경우 제거됨.
미제거 유형
- (추측)주요 속성(후보키 부분 집합)이 주요 속성(후보키 부분 집합)에 종속하는 경우
BCNF 정규형을 만들어봅시다! 주요 속성이 비주요 속성에 종속합니다. 안일어날 것 같은 일인데 일어나네요. 인간의 실수 때문이라고 생각합니다. 함수 종속을 제거하기 위해 릴레이션을 분리해봅시다!

6. 프로젝트 적용
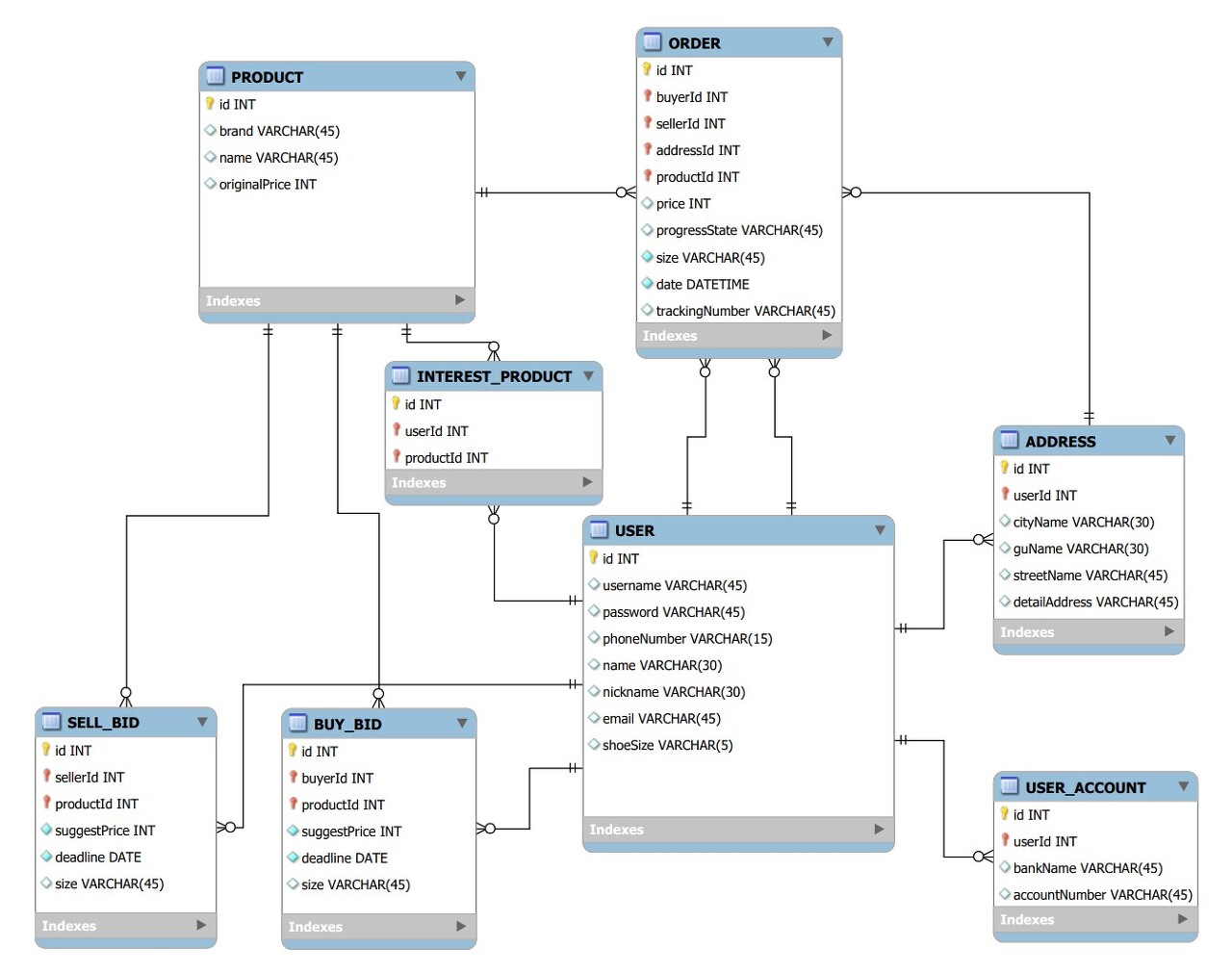
아래 ERD는 크림 앱을 클론한 프로젝트의 ERD 설계 결과입니다. 저희 팀은 제3 정규형이면서, 모든 결정자가 후보키를 만족하는 BCNF 정규형을 선택했습니다. 프로젝트의 초기 단계이기 때문에 ERD를 보수적인 정규형을 선택하는게 맞다고 생각했습니다. 추후 성능 개선 필요점이 생긴다면, 역정규화를 이용하여 테이블 참조를 줄일 계획입니다. 또한 primary key를 테이블에 존재하는 비즈니스 데이터 속성 값(ex.주민등록번호)을 사용하지 않고 DBMS에서 자동으로 생성해주는 id 값으로 설정했습니다. 비즈니스 데이터 속성 값은 어떤 이유에서든지 바뀔 일이 있다고 판단했습니다. 주민등록번호 같은 경우도 안바뀔 듯 하지만, 사람이 충분히 많다면, 일년에 한두번씩 바뀌게 되죠. 따라서 절대 바뀌지 않는 값은 DBMS에서 자동으로 생성해주는 id를 사용하는게 맞다고 생각했습니다.
7. 마무리 질문
- 왜 제2 정규형는 제1 정규형이 필수로 선행돼야 할까요?
- Ans. 제1 정규형은 관계형 데이터 모델이 가져야할 구조를 정의하기 때문입니다. 만약 속성의 값이 릴레이션이 된다면 관계형 데이터 모델이 아닌 계층형 데이터 모델이 될겁니다. 이는 관계형 데이터 모델이 안되죠. 실제로 sql은 제1 정규형을 만족하지 않은 릴레이션 형성을 금지[2]하고 있습니다.
Most relational database management systems do not support nested records, so tables are in first normal form by default. In particular, SQL does not have any facilities for creating or exploiting nested tables. Normalization to first normal form would therefore be a necessary step when moving data from a hierarchical database to a relational database. [2]
- 왜 제3 정규형은 제2 정규형이 필수로 선행돼야 할까요? 실제로 제3 정규형의 조건인 '비주요 속성 -> 비주요 속성' 함수 종속성 해결은 제 2정규형 때 하는 '후보키 부분 집합(후보키 내 속성) -> 비주요 속성' 함수 종속성 해결과 위치를 바꿔도 무관합니다. '후보키 부분 집합(후보키 내 속성) -> 비주요 속성 -> 비주요 속성'의 함수 종속성이 있는 릴레이션을 생각해보죠! 앞을 먼저 끊든 뒤를 먼저 끊든 아무 문제가 없습니다. 근데 왜 우린 앞을 먼저 끊어야할까요?
- Ans. (개인적인 판단) 제 2정규화가 제3 정규화보다 더 많이 필요하기 때문입니다. 즉 '후보키 부분 집합(후보키 내 속성) -> 비주요 속성' 종속성이 '비주요 속성->비주요 속성' 보다 많기 때문이죠. 모든 일은 필요로 인해 생깁니다. 마치 어샘블리어가 불편해서 c언어가 생긴것 처럼요. 처음에는 전자가 더 많이 일어나서 이를 정규형 형태로 규정해야 했을겁니다. 이후 후자도 많이 일어나니 이 또한 정규형 형태로 규정하게 된거죠. 생각해보면 제3 정규형이 가지는 문제인 '주요 속성이 비주요 속성에 종속하는 경우'는 제1 정규형이 가지는 문제인 '비주요 속성이 주요 속성에 종속하는 경우'는 적을 것으로 예상됩니다. 실제로 각 정규형은 Edgar F. Codd에 의해 1년에 한번씩 발표됩니다. 점점 필요했기 때문이죠.
- 제 1정규화를 하면 제2 혹은 3 정규화까지 만족시키는 경우도 있습니다. 왜그럴까요?
- Ans. 각 정규화는 포함관계가 존재하도록 정의됐기 때문입니다. 이행적 종속이 없고 부분 함수 종속성이 없더라도 특정 속성 내에 단일 값이 아닌 릴레이션 값이 존재한다면 이는 UNF(Unnormalized form)입니다. 제2,3 정규형 모두 1정규형이 선행돼야하기 때문이죠.
- 정규화 상태는 높을 수록 좋을까요?
- 쓰기를 정확하게 해야할 때는 정규화 상태는 높은게 좋고, 쓰기에 비해 읽기 성능이 좋아야할 때는 정규화 상태가 낮은게 좋습니다. 정규화 단계가 높아질 수록 신경 써야하는 함수 종속성 관계가 많아지기 때문입니다. 결국 트레이드오프인거죠. 트랜잭션 고립성 수준을 어느정도로 결정할지도 같은 맥락입니다. 고립성 수준을 높일 수록 정확한 데이터 읽기와 쓰기가 되지만 성능이 안좋아지죠.
- 역정규화란 무엇일까요? 이걸 왜할까요?
- Ans. 일부 쓰기 성능의 손실을 감수하고 데이터를 묶거나 데이터의 복제 사본을 추가함으로써 데이터베이스의 읽기 성능을 개선하려고 시도하는 과정입니다. 정규화 상태가 꼭 높은게 좋은게 아니기 때문입니다. 우리는 때론 쓰기를 덜 정확하게 하는 대신 좋은 읽기 성능 이점을 얻어야하기도 합니다.
출처
[1] Data normalization, en.wikipedia.org, 05/04/2022
[2] First normal form, en.wikipedia.org, 05/04/2022
[3] Second normal form, en.wikipedia.org, 05/04/2022
[4] Third normal form, en.wikipedia.org, 05/04/2022
[5] Boyce–Codd normal form, en.wikipedia.org, 05/04/2022
'데이터베이스(DB)' 카테고리의 다른 글
| 도커 이미지 저장소 선정 과정. Docker-hub, AWS ECR, AWS S3 비교 (0) | 2022.09.05 |
|---|---|
| Session storage 선택 과정, Redis vs Memcached (0) | 2022.09.05 |
| [DB] 이상현상이란? 함수 종속성이란? 꼬리 질문하며 살펴보자. (0) | 2022.05.01 |